2022-03-02

2022年2月25日,nextionBI举办线上发布会,这是下一代BI首次正式与大众见面。nextionBI的定位是数据融合的增强分析型敏捷BI平台,面向知识设计,关注知识的积累、发现与应用。这一定位里的核心是增强分析,但是这一概念与BI怎么结合,在具体场景中如何应用,这是发布会上很多观众关心的问题。因此,数睿数据AI科学家车文彬博士,借此机会从发布会上介绍一个特性“数据解读”切入,为大家详细介绍nextionBI的增强分析的实现过程与最终效果。
01.为什么要做数据解读?
数字化、大数据、数据分析这些概念大家已不再陌生,不管是大企业还是小公司,都明白基于量化的业务数据进行分析,得到的结果有助于快速厘清业务现状,发现异常数据及时识别经营风险。懂这个道理的人很多,但是真正完成这个目标并不是那么简单。
对于一些对数据不敏感的人来说,看数据是个头疼的事情。自己看不懂,交给数据分析师看,分析师给出的分析报告,又有很多专业名词,虽然是中国话,但还是听不懂。同时对于专业数据分析师来说,从零开始看一张“大宽表”也是一件头疼的事情,几百个维度,千万条数据,老板要求数据拿到之后立刻马上就要看结果,分析师也只能简单拉个折线图、饼图,就开始大谈特谈。这样也许一次两次能忽悠得了老板,但是专业的数据分析师都知道这种方式其实很难产出对于业务真正有价值的信息。严谨的数据分析需要搜集大量数据,尝试多种统计方法和算法模型,才仅仅有可能发现一些隐性联系。这种情况下如果能够有人提前看一下数据给出一个基础判断,对于分析师开展深度分析会有很大帮助。但在绝大多数情况下,这个基础分析也只能分析师自己来做,属于低效率的重复劳动。
如果能让数据能够主动说“人话”,像为钢铁侠服务的“贾维斯”那样,让管理人员能够快速听到数据反映的基本趋势和潜在风险,让专业人员能够对数据全貌快速做到心中有数,就可以很大程度上提高数据分析工作的效率。数据解读功能的初衷就是帮助用户快速地了解数据,发现数据表层以及潜在的信息,从而可以更快地进行分析以及利用数据价值。
02.如何让数据说“人话”?
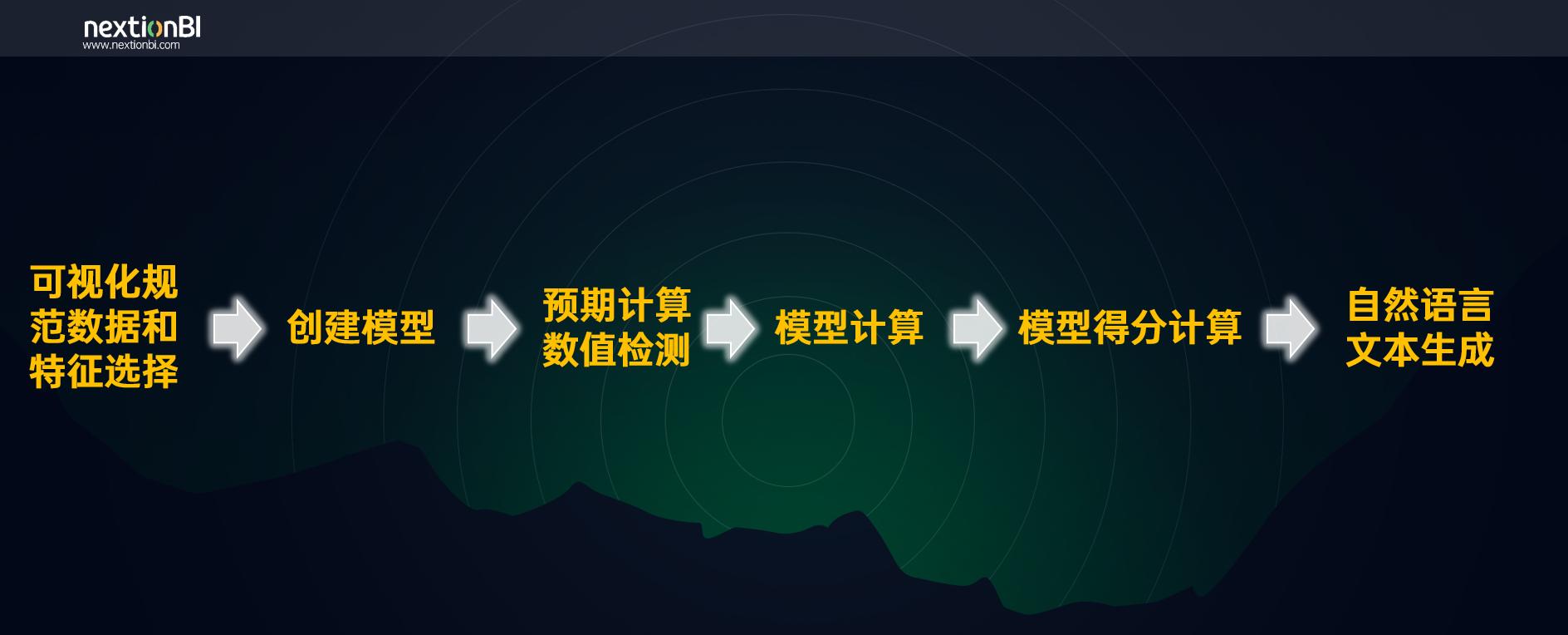
nextionBI利用统计学、机器学习对数据特征进行分析建模以及自然语言处理,从而生成通俗易懂的数据解读。本次发布的数据解读能力包括三个功能模块:表格描述、图表描述以及单点解释。接下来分别详细介绍每个模块的技术特点。
表格描述功能会对用户导入的数据表格进行内容提取,对表格的标题以及字段进行关键词提取,关键词提取可以在一定程度上精简文本内容让人们便捷地浏览和获取信息。利用深度学习算法对提取的关键词进行分类,可以判定表格数据所属的行业领域,分类准确率达到95%以上。目前我们收集的领域包括(医药、汽车、财经、食物、法律)等,后续也会根据具体业务场景不断地丰富语料,支持更多领域的识别,针对不同领域生成不同的数据解读。对数据进行字段类型的判别,在数据显性层面:对数据进行值的统计,分类类别统计,空值以及异常值检测,时间趋势、变化趋势以及同比环比的计算;在数据隐性层面挖掘数据潜在的联系:1)利用皮尔逊系数发现数据之间的相关性,发现两个变量之间的线性相关程度,虽然不能反映因果关系,但用户可以根据自己的行业知识进行判断。例如销量与利润。2)利用FP-Growth算法进行关联分析,在数据复杂度以及计算效率上相较于Apriori算法都有不错的提升。关联分析描述了一个事物中某些属性同时出现的规律和模式。如“67%的顾客在购买啤酒的同时也会购买尿布”,因此通过合理的啤酒和尿布的货架摆放或捆绑销售可提高超市的服务质量和效益。结合上述分析的特征,利用深度学习主题生成模型生成连贯性解释性强的数据解读,帮助用户做出决策,更好的利用数据价值。
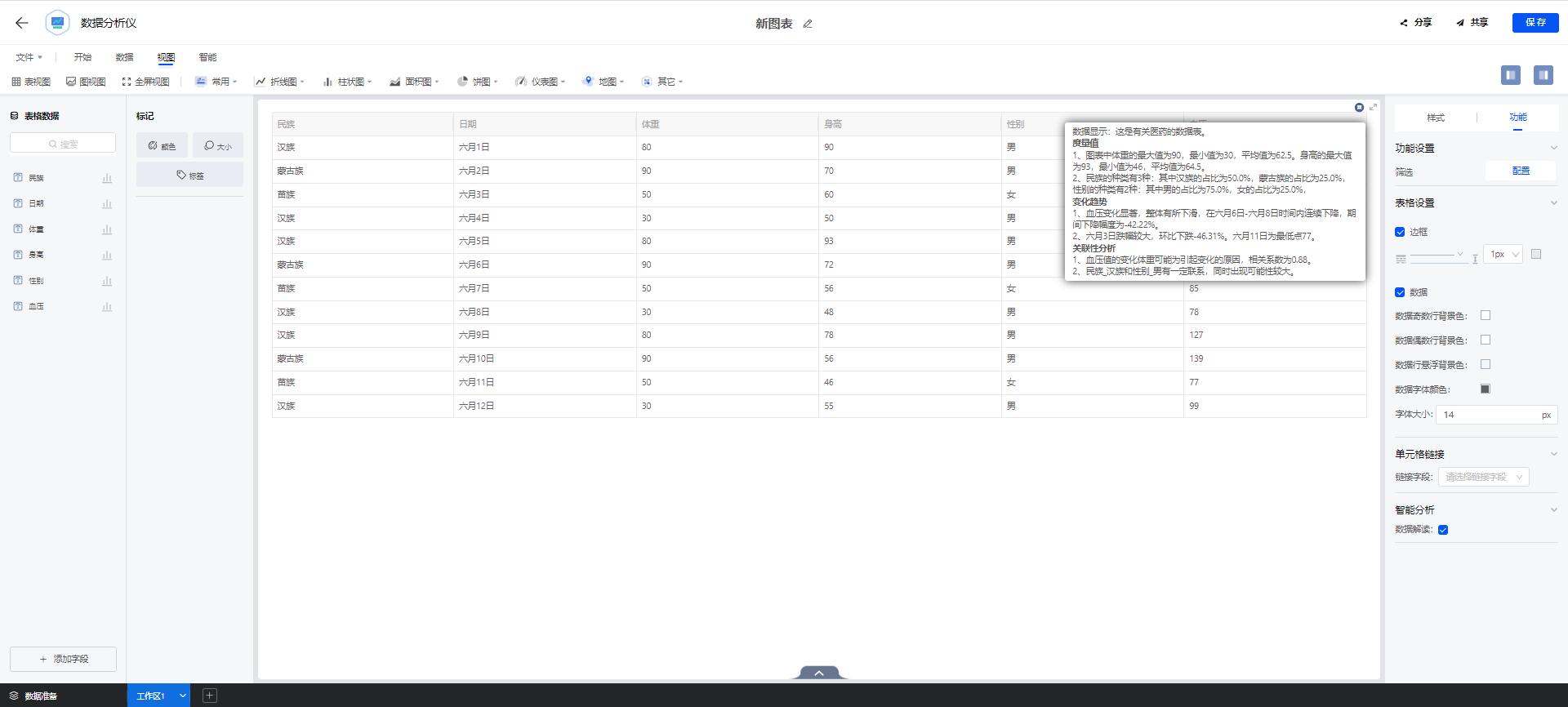
图的形式是为了更直观地看清楚数据整体情况,但很难看到背后的数据。所以图表描述功能需要对可视化视图背后的数据进行解读,帮助用户更好的了解数据,结合自己的行业理解写出完美的分析报告。在表格描述的基础上融入了图表的特性,针对不同类型的图表可以生成不同的解读。例如:柱状图侧重量的对比,折线图侧重趋势变化,饼图侧重占比等。在文本生成过程中,我们融合了规则模板和文本生成模型,其中为保证文本的可读性,文本生成模型采用了一种自监督的可控文本生成方法。可控文本生成的目标,是控制给定模型基于源文本产生特定属性的文本。在数据解读中使用的特定属性包括影响文本的领域、主题、实体和风格等。
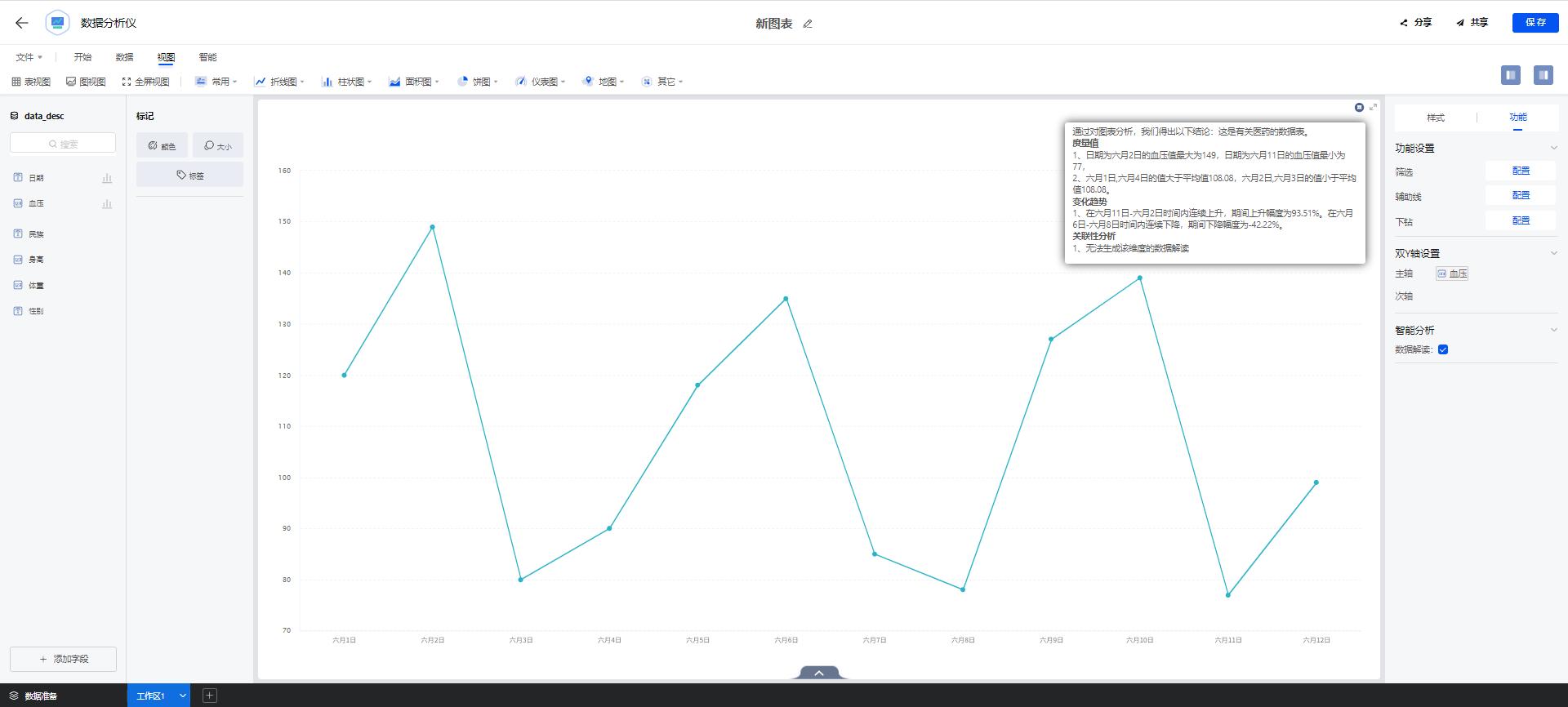
单点解释是对数据表格以及可视化图表中的单个数据点进行解读,该数据点须为聚合计算后的数据,通过算法结合原始数据可以分析出这条数据的组成、分布以及与其他数据的不同之处。通过对数据点进行分析,对应原始数据通过机器学习算法自动选择特征、数据建模、模型评估选取得分比较高的特征,通过自然语言处理(NLP)对语义进行理解结合槽位填充生成数据解释。
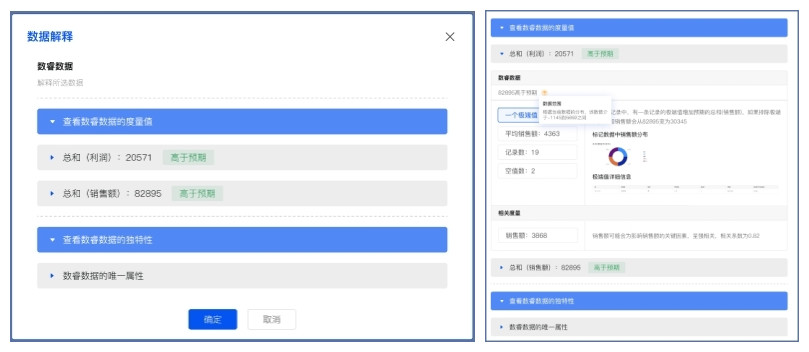
单点解释主要针对可视化图表底层的数据进行度量值以及独特性两方面解释:度量值指的是组成聚合特征的数据,包括(平均值、极端值、记录数、空值)并且分析这些维度对聚合特征预期值的影响。预期是我们将原始数据的其他数据作为先验训练数据,通过贝叶斯建模,标记数据作为预测数据进行运算得出的结果。通过分析每个维度对预期值的影响,生成相应的数据解读。独特性分析主要是为了所选标记与其他数据之间的区别,用户可以根据该维度特性进行专业分析,挖掘背后的原因,引导激发用户分析灵感。
03.nextionBI数据解读效果如何?
我们选择目前市场上主流的BI平台进行对比,国内包含此功能的平台较少,故我们选择国外同样具备该数据解读能力的产品进行功能对比。
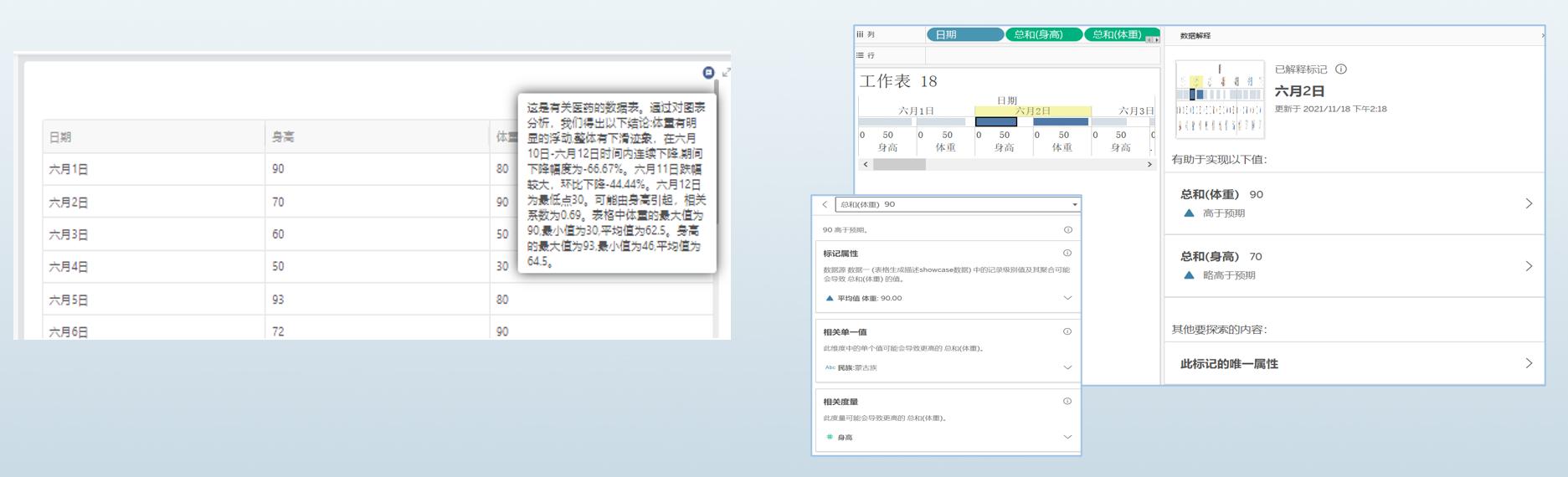
首先我们选择目前数据分析师使用较多的T BI产品进行对比,如上图所示,针对同一组数据进行数据解读,左图为nextionBI解读结果,右图为T BI产品的解读结果。
在描述维度方面,nextionBI针对于整个表格,涵盖了多维度描述信息,T BI产品只针对于单个数据,利用单一贝叶斯模型分析预测。
在使用范围方面,nextionBI可适用于多列、多种数据类型组合,而T BI产品对维度和数据类型均有一定限制。
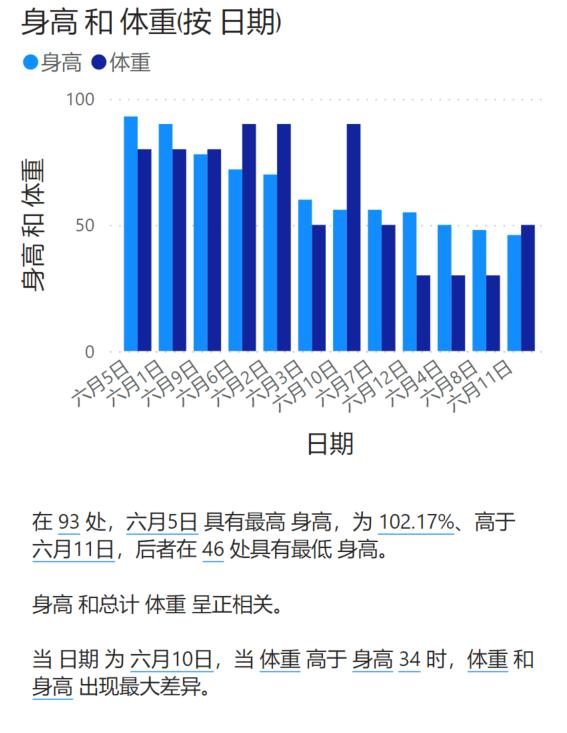
我们也对比了某老牌厂商的P BI产品,针对同一数据的完成情况如上图所示。nextionBI的结果涵盖了分类、同比、环比、相关性分析、覆盖纵向横向等各个维度的描述信息,融合多个模型及规则信息较为丰富,P BI更多关注统计特性。同时nextionBI结果的可读性更强,更符合中文数据汇报的表达习惯,整体上更加通顺也更易理解。
总体来说,nextionBI作为后起之秀,在数据解读能力的设计和开发方面,全面分析市场上目前的能力水平和核心需求,针对性地进行研发和技术攻坚,在描述维度、中文可读性、适用范围都积累了自己的优势。在本次发布会之后,我们将充分收集用户体验之后的反馈,不断优化算法设计和功能体验,希望最终能让人人尽享数据价值。

